Building a fault tolerant web service
I’ll talk about a system design problem and how to approach it from a Software Architect’s point of view.
Problem statement
Design a high-performance, scaled, cross - geo, web service which would be accessed by millions of users. For reference we can consider a service like Reddit.
Non Functional Considerations (Requirements)
While we won’t be analyzing the actual functional design of the web service, we need some idea about the non-functional ones.
Priority -
-
Reliability (Also known as Partition tolerance) - The system should be able to handle outage of servers and other components. That is, if a server goes down, it shouldn’t result in the backend throwing 5xx errors.
-
High availability - The core services should always available for users to consume.
-
Consistency - It’s okay if posts/ comments are displayed inconsistently.
Other than the basic non-functional requirements we have a couple more to consider, all of them extension of the first priority ‘Reliability’ -
- Health monitoring and alerting - Health of services should be constantly monitored. Any issue should be alerted.
- Recovery and failover - In case of failed server, system should be auto recovered.
- Backups and resilience - In case of disaster e.g. data center is taken down. Service should have minimal impact.
Availability SLA
Generally we come up with SLAs for the services in terms like percentages. Sometimes called “five nines”.
| Availability SLA (%) | Allowed Downtime per Year |
|---|---|
| 99.0% | 3 days, 15 hours, 36 minutes |
| 99.5% | 1 day, 19 hours, 48 minutes |
| 99.9% | 8 hours, 45 minutes, 36 seconds |
| 99.95% | 4 hours, 22 minutes, 48 seconds |
| 99.99% | 52 minutes, 35 seconds |
| 99.999% | 5 minutes, 15 seconds |
| 99.9999% | 31.5 seconds |
Getting to such SLA involves things more than just the design of system. We need to design the processes, investments and resources to match the SLAs.
Things like Software Lifecycle process - Agile/ Waterfall, testing strategies, A/B testing, Feature rollout impact the SLA much more than the system itself.
Estimating Traffic
Assume an approx Daily active users – 1 Million.
Assuming everyone uses the app for 5 minutes in average, with about 1 request (user action) every 30
seconds. Which means Every user will generate (5 * 60) / 30 = 10 requests per day.
If the spread of load is even throughout the day it means – 1 million * 10 = 10 Million requests
per day. This becomes – 10,000,000/24*3600 requests per second ~ 0.1 transactions per second
or 1 transaction every 10 seconds.
However, in real life we don’t get even spread, chances are people use social media like Reddit off work hours more than office hours. In short we have to plan for a range of traffic instead of one.
This is especially relevant in modern cloud based architectures where you can scale up and down based on heuristics and metrics, which can save significant amount of costs.
Ideally we will come up with actual numbers based on historic data and user behavior. But we need something to start with. So let’s assume a spread of 10:1 peak vs average.
Numbers
| Scenario | Expected Traffic |
|---|---|
| Average RPS | 0.1 rps |
| Peak RPS | 10 rps |
The task at hand is to balance the expected load with the non-functional requirements in minimum cost possible. A system that supports the team to achieve SLA given perfect execution of the software process.
Because it’s always possible to get more and more power machines, throw money into fancy SAAS offerings to manage the traffic. The trick is to do it efficiently.
Frankly speaking the numbers we see here are not very high. A single server running async rust along with a separate instance of a database can easily handle this traffic for transactional workloads.
The problem comes when something goes wrong. We can’t have A/B deployments without downtime. We can’t fallback to anything when the single database server goes down.
Overall Design
We will start with a basic server and a database. The application logic will be written in the application server, which will query the information from the database.
State will be maintained by combination of keys from the client, in form of cookies and auth token, or even query parameters and header variables along with actual data stored in database.
The DB will be hit whenever any information is required.
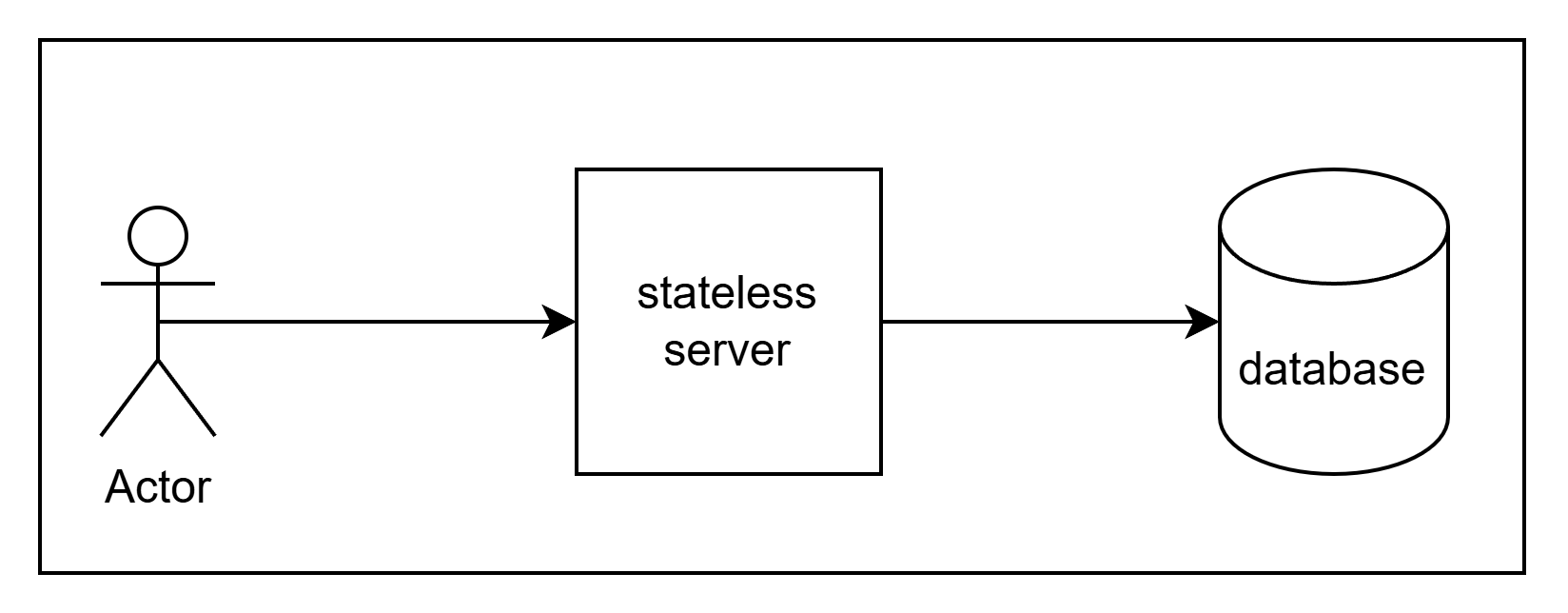
Now as traffic increases, will be start hitting bottlenecks. The first one would be database. Querying is an expensive operation. Baring increasing the capacity of the database server. We start by implementing a cache. The most basic way to achive this would be to use a simple in memory cache within the application server.
Note: Cache is a performance optimization mechanism. We leverage it to not have to re-compute complex business logic which takes time for. e.g generating recommendations, feeds etc. Reducing load on database as well as query fetch performance.
However this soon reaches a limitation where our application server itself does is unable to keep up and we now need multiple instances of it. So we create a load balancer and multiple instances of the server behind it.
But adding multiple instances of the server means, we can no longer maintain an in-memory cache within the server since that breaks statelessness. To solve that, we introduce a distributed cache.
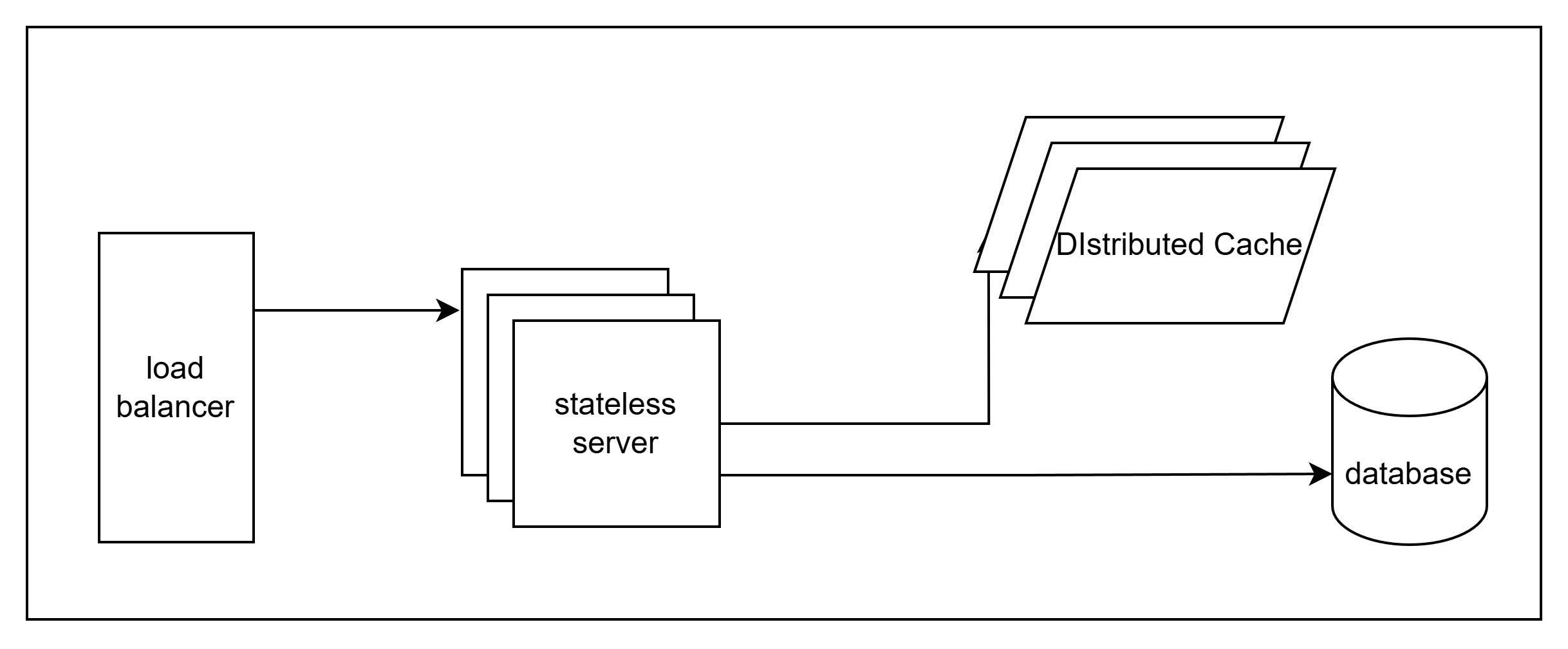
This distributed cache now allows us to cache information without to make expensive database calls every time a query is made.
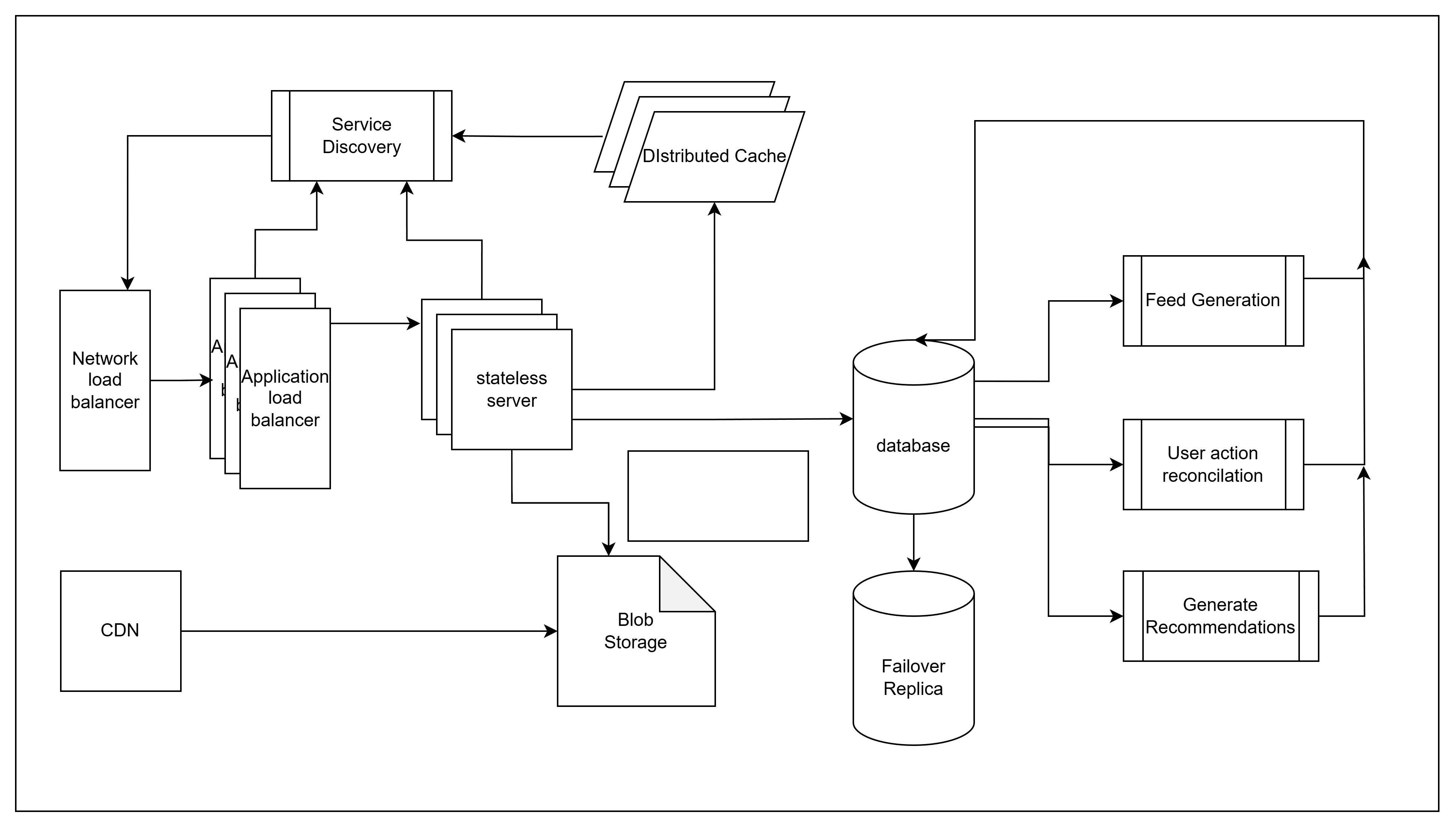
When including a CDN and network load balancers and a service register to track the instances of different server. We will end up with something like this -
Using cache
There are several layers of cache when talking about compute - from CPU cache to disk cache to application level or even system level cache.
We are interested in three types of cache from a high performance backend perspective -
-
Database cache- each database system will have their own cache mechanism to ensure they don’t hit the slow storage again and again. Fortunately this isn’t something we need to worry about as the software server handles this own it’s own.
-
Resource Cache - Static assets like images, sounds, css, html, js, pdf, and anything else in the world which isn’t dynamically generated can and should be cached. This starts with being cached in user’s machines and moves to being cached in cloud via services like a CDN (Content Distribution network).
-
Application Cache - While database optimizes disk hits. Hitting the database server itself can be expensive. Not to mention expensive as well since database servers tend to be the more expensive part of the infra. Hence we implement application layer caching.
Application layer cache
These caches are not transparent to application programers. As in, unlike CPU, filesystem or database caches. The programer explicitly needs to use these caches. For example -
def get_feed(user_id):
if user_id not in getFeedCache():
feed = generateFeed(user_id)
getFeedCache()[user_id] = feed
return feed
return getFeedCache()[user_id]
Cache becomes part of the tools available to developers to optimize the resource usage. This helps
both speeding up the application as well as reduce load on the database.
Designing the cache
The sub system of the distributed cache is it’s of separate system with it’s own design. The cache
in general will have multiple instances running with each key mapped to a specific instance.
Here we need to come up with a constant method of ensuring 1 key is always hashed to a specific instance of cache server always. For this we can leverage a conveniently named technique called “Consistent Hashing”.
Consistent hashing
A simple method where all cache servers mapped in a circle. Every hash algorithm produces a fixed size binary output. This mean it can be mapped to an int value with a deterministic minimum and maximum.
The algorithm creates a circle where max + 1 == min. Now each cache server is mapped to a specific
hash value.
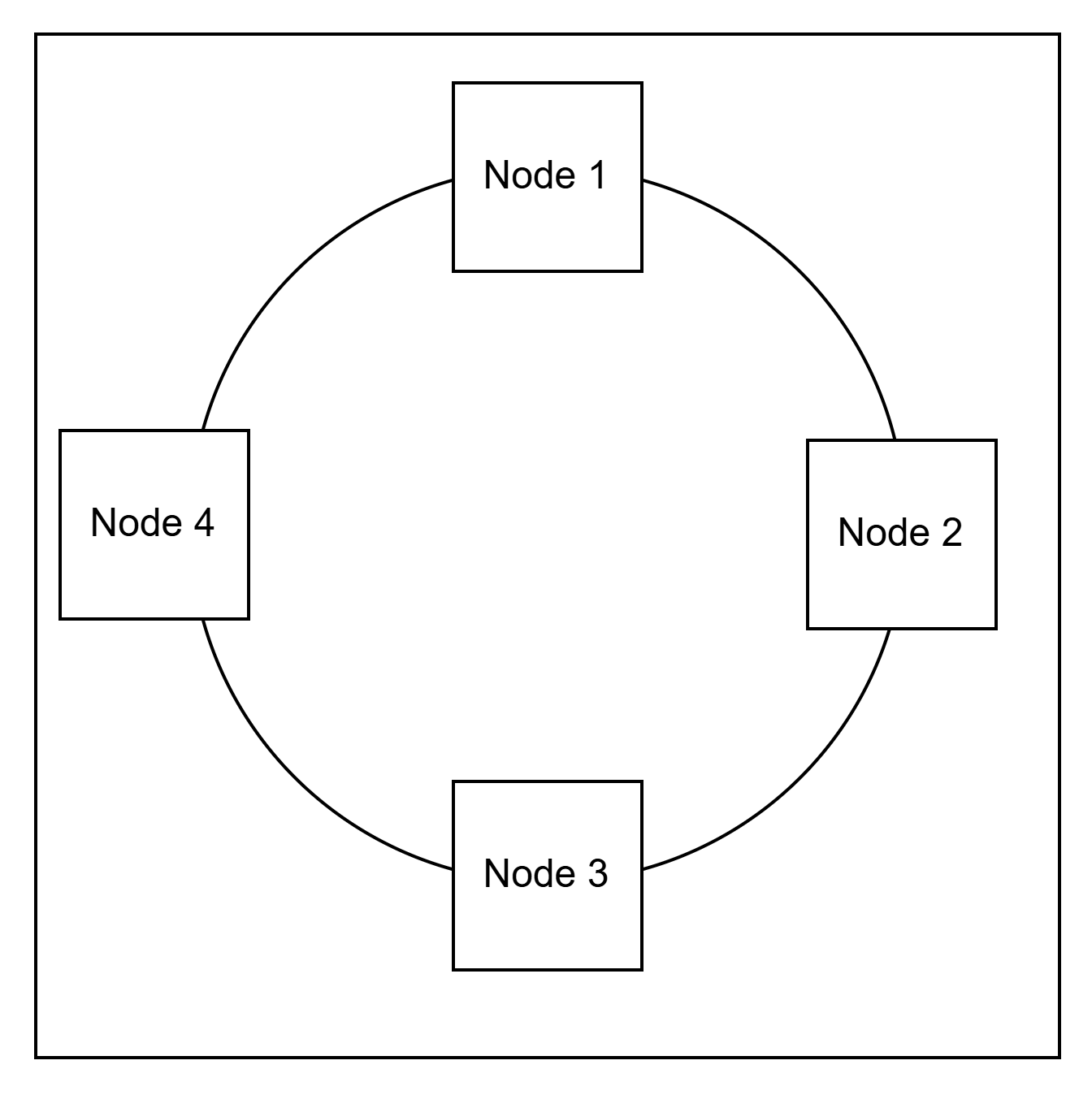
Then there would be function similar to getNode(key) which is implemented by a simple logic -
def findKeyNode(key):
hash = calculate_hash(key)
for node_hash in getNodes():
if hash <= node_hash:
return nodes[node_hash]
# if key is larger than the last node, then it wraps around to the first node.
return nodes[0]
Softwares like redis generally provides a implementation of the consistent hashing (or equivalent) as part of their SDK so it shouldn’t be something that needs to be implemented most of the times.
Replicas
Unlike stateless application servers, cache is used to maintain state. So when a cache goes down we need a strategy for handling it and to failover to a separate instance.
Depending on the software architecture this might not require moving the stored keys to the next node. Instead just simply deleting the failed node from the hash circle might be enough.
For this post, we will assume we need to preserve the keys because we don’t want to lose the data, e.g. user’s generated feed is only stored in cache.
To achieve a failover where data is preserved, we will require a “replica”.
Replica: is a server node whose sole purpose is to replicate the data/ state in it’s master node and get promoted to master in case the master node fails.
Generally you start with 1 replica and add more as the business use case. E.g. for critical applications you might want 3 or more replicas.
In general all distributed softwares should provide a mechanism of replication. If a specific
software doesn’t. Then a wrapper service/ interface will need to be created to handle replication.
This service will ensure a “write” request is complete only till x replicas
acknowledge it. Simplest is N/2 + 1 to ensure majority is updates.
Quorum based Consensus protocol
Depending on your consistency requirement, the quorum amount changes. The quorum to update the state is the consensus protocol of the system and specifics of it determine the consistency level of the system.
The more consistent you want things to be - the more time it takes for a write operation to complete.
There is a famous rule to achieve consistency of data R + W > N. Which means sum of Read replicas
required to read a value and Write replicas required to update a value should be greater
than total number of replicas. This ensures should be overlap between write and read operations.
These values can be tuned to get the desired consistency levels.
Database
Based on our traffic requirements we had figured out that a single instance database can achieve our required QPS. However, this leaves our system at the mercy of this single instance.
Just like with cache, we need replication to ensure our system is fault tolerant. Since we are designing a social media service, overall eventual consistency is enough for most work loads.
Note: There would be some sub systems here which are an exception. E.g. Authentication. A password change or a log out should reflect immediately everywhere.
Database Replicas
For a basic tolerance we can start with two read replica that will serve as a failover node to ensure high availability.
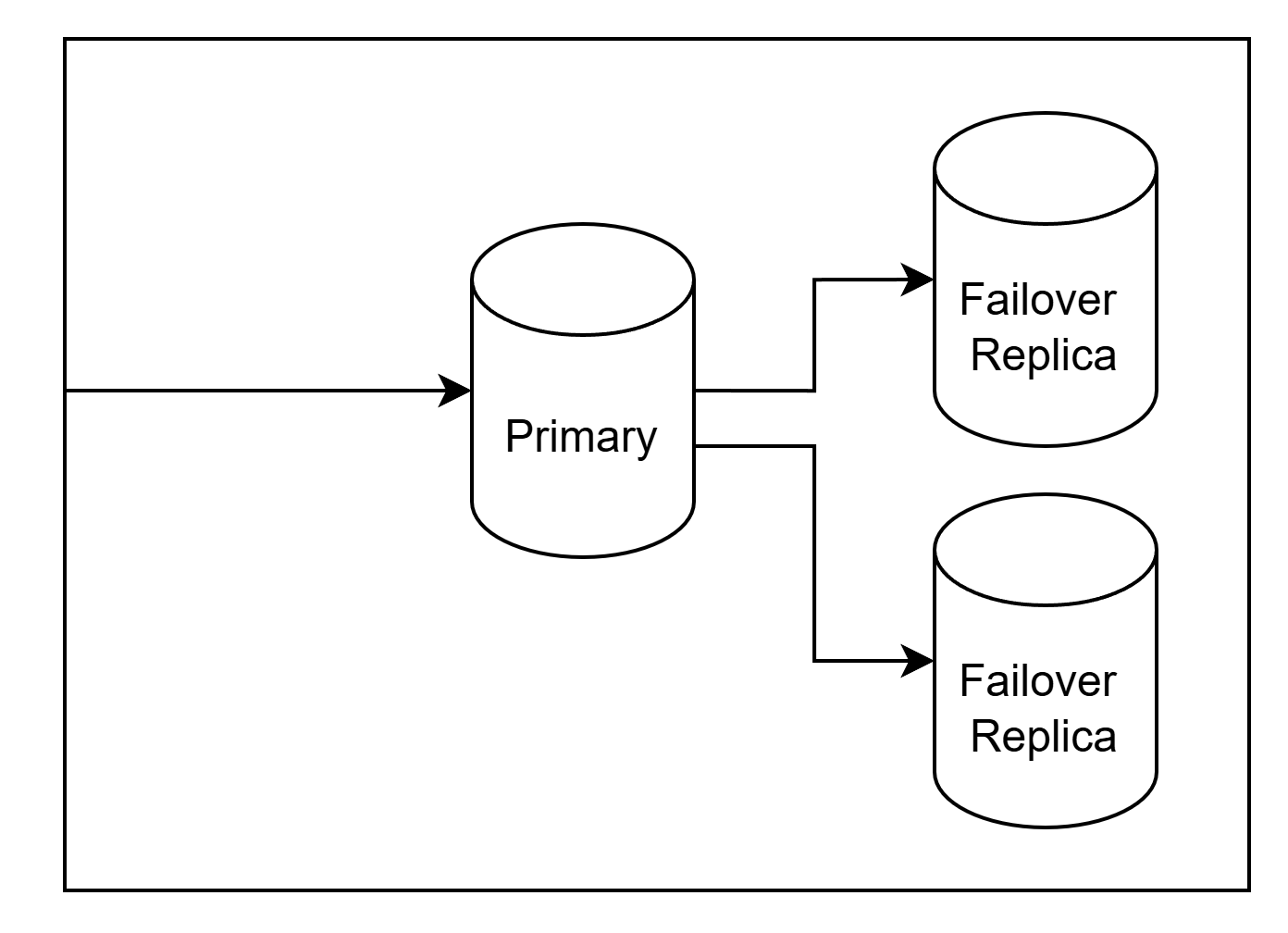
To balance cost and tolerance we can have multiple replicas with only 1 running as a failover candidate. The other replicas can be running in much smaller compute to save costs. And scaling up only when the senior most node gets promoted to primary.
When working with multiple read replicas. The question of consensus comes here as well. When do you mark a write successful?
-
For highly consistent/ fault tolerant system. We will need to get acknowledgement from all read replicas. Resulting in slower writes.
-
For applications like a social media, things like comments/ like being little inconsistent between users or even different session of same user is something we can live with. Hence we can have less consistent reads with faster writes.
At this stage we don’t need to create multiple write replicas. Those complicate the equation quite a lot. But for the scale of 10 QPS, even 100 QPS. A single write server would be able to handle it with ease.
If we start seeing query performance degradation, we can profile and start considering data partitioning to further scale the servers. A good news is, it’s generally easy to partition (aka Shard) the data geographically. Allowing different write replicas handling different partitions in different geo. Resulting in better local performance and reduced load on the servers.
Conclusion
We need the following components for a high availability transactional system to ensure robust up time and reliability.
- Load balancer
- Service registry
- Stateless application servers
- Distributed cache servers
- Database servers with replica
Spreading the replicas across data centers will complete the fault tolerance of the system. This will let us have working failover in case of disasters.